Using Github Actions as janky serverless infrastructure
Replace your tiny VPS with a Github repo today!
The Requirements
For an ongoing effort to build some infrastructure for a university club 1 I’m starting, I needed to aggregate RSS feeds into a single hosted megafeed, in order to further pipe this feed to a Discord bot, among other things. In practice, this would mean setting up a VPS, downloading some combiner script off of Github and setting up a cron job to download, run, and upload on a regular basis. One could also haphazardly use one of the multitudes of online services that do this, the downside being clunky modification, nonportability, arbitrary restrictions, and of course the Sword of Damocles that hangs over every small scale web startup.
In my search, I found a Github repo innocently called rss-combine which did something pretty interesting (and might help someone with the same problem).
The Repo
The code in the repo looks pretty normal. For the VPS solution, the Go code would actually have been sufficient to download and combine the feeds to a single file. But what are these commits?
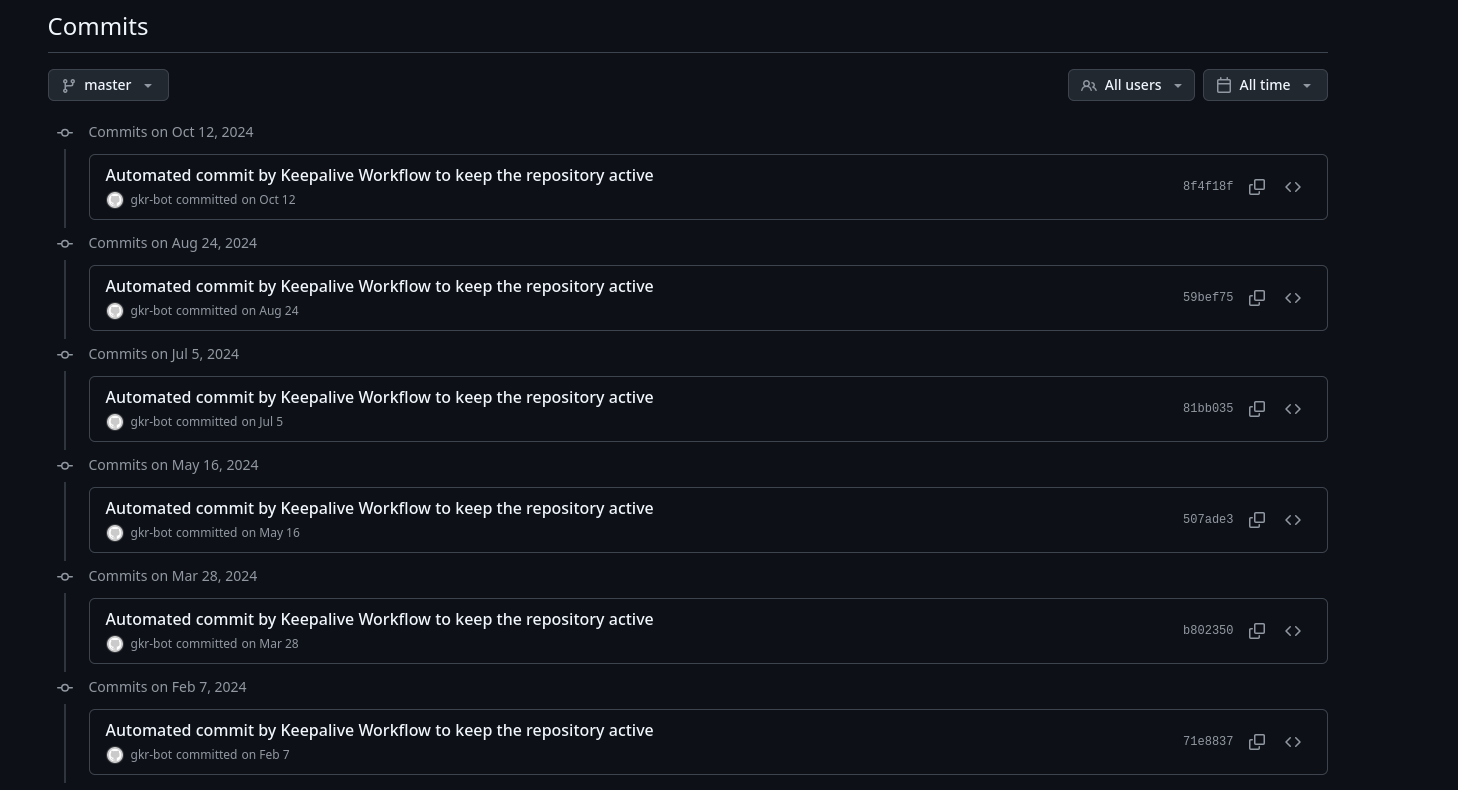
They seems to be caused by this action, which is designed to keep your repo “active” for cron(!) based action triggers. Understandably these kinds of actions have alot of compute cost, while being offered for free, so it makes sense why Github would try limiting them for untouched repos. Lets take a look at some of the cron-based actions rss-combine is trying to preserve.
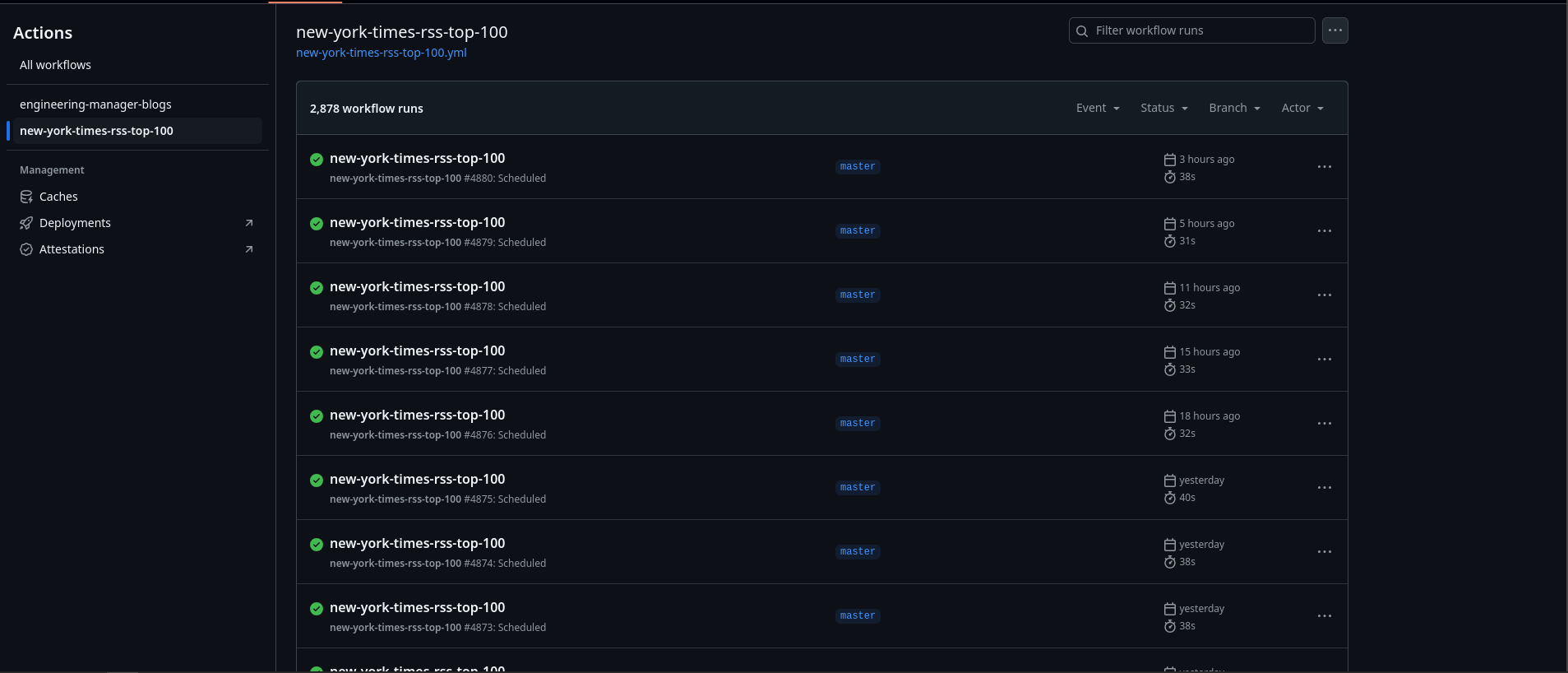
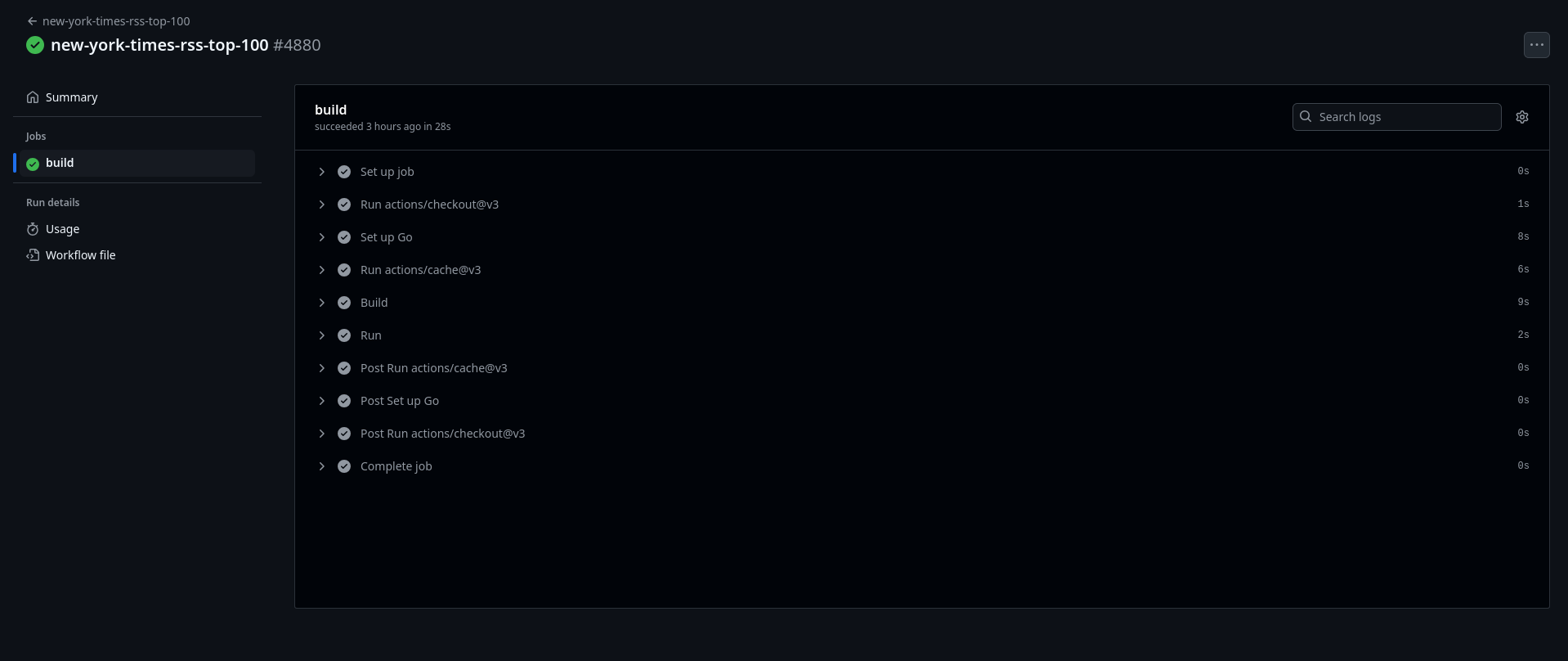
The actions seem to be running the repo itself!
...
env:
AWS_ACCESS_KEY_ID: $
AWS_SECRET_ACCESS_KEY: $
AWS_REGION: us-west-2
RSSCOMBINE_TITLE: "New York Times Top 100 Articles a Week"
RSSCOMBINE_DESCRIPTION: "Combines public New York Times RSS feeds into one feed, with the goal of surfacing only the top items"
RSSCOMBINE_AUTHOR_EMAIL: "***"
RSSCOMBINE_AUTHOR_NAME: "***"
RSSCOMBINE_FEED_LIMIT_PER_FEED: 5
RSSCOMBINE_FEED_URLS: "https://raw.githubusercontent.com/chase-seibert/new-york-times-rss-top-100/master/README.md"
RSSCOMBINE_LINK: "https://github.com/chase-seibert/new-york-times-rss-top-100"
RSSCOMBINE_S3_FILENAME: "new-york-times-rss-top-100.xml"
...
Using the built in “upload to S3” functionality, it seems to be uploading the resulting feed to a predetermined bucket, presumably for public access. Neat.
Adapting it
The final result is here if you want to follow along.
Looking at the workflow file (located in .github/workflows in the repo), all of the required config could be done by just changing the env variables in the config. A particular snag was that the config s3_bucket, with which the code determines whether the output is uploaded to s3 or piped out stdout, was not present in the env. This was because it was located in rsscombine.yml, which I pruned all redundant config from.
run commands are run with the os’s default shell (for ubuntu bash) so I’m able to do this
...
run: go run rsscombine.go > feed.xml
...
And then
...
run: curl -F "feed.xml=@feed.xml" "https://$:$@neocities.org/api/upload"
...
Thankfully neocities’ upload system is dead simple so there was no problem there. If you want to run a similar setup, both my and the originals are there for you to model your workflow config off of. Thanks for reading!
-
A weblogging and homebrew website club. The website is sparse at the time of publishing, and is only linked for posteritys’ sake. ↩